Beyond English: Why True AI Data Analysis Must Be Global
The Datum Fuse Team
September 21, 2025

In the world of data, numbers are a universal language. But the context that gives those numbers meaning—the product names, the customer feedback, the market categories, the survey responses—is not. It’s written in English, Spanish, Korean, Japanese, Arabic, and thousands of other languages that power global business.
For any data tool that claims to be "intelligent," handling this diversity isn't just a feature; it's the absolute baseline.
Yet, for countless analysts, marketers, and researchers, this is a daily point of failure. You upload a perfectly good dataset from your team in Seoul or your survey of customers in Paris, and you're met with a wall of gibberish, cryptic errors, or the dreaded empty white boxes: □□□.
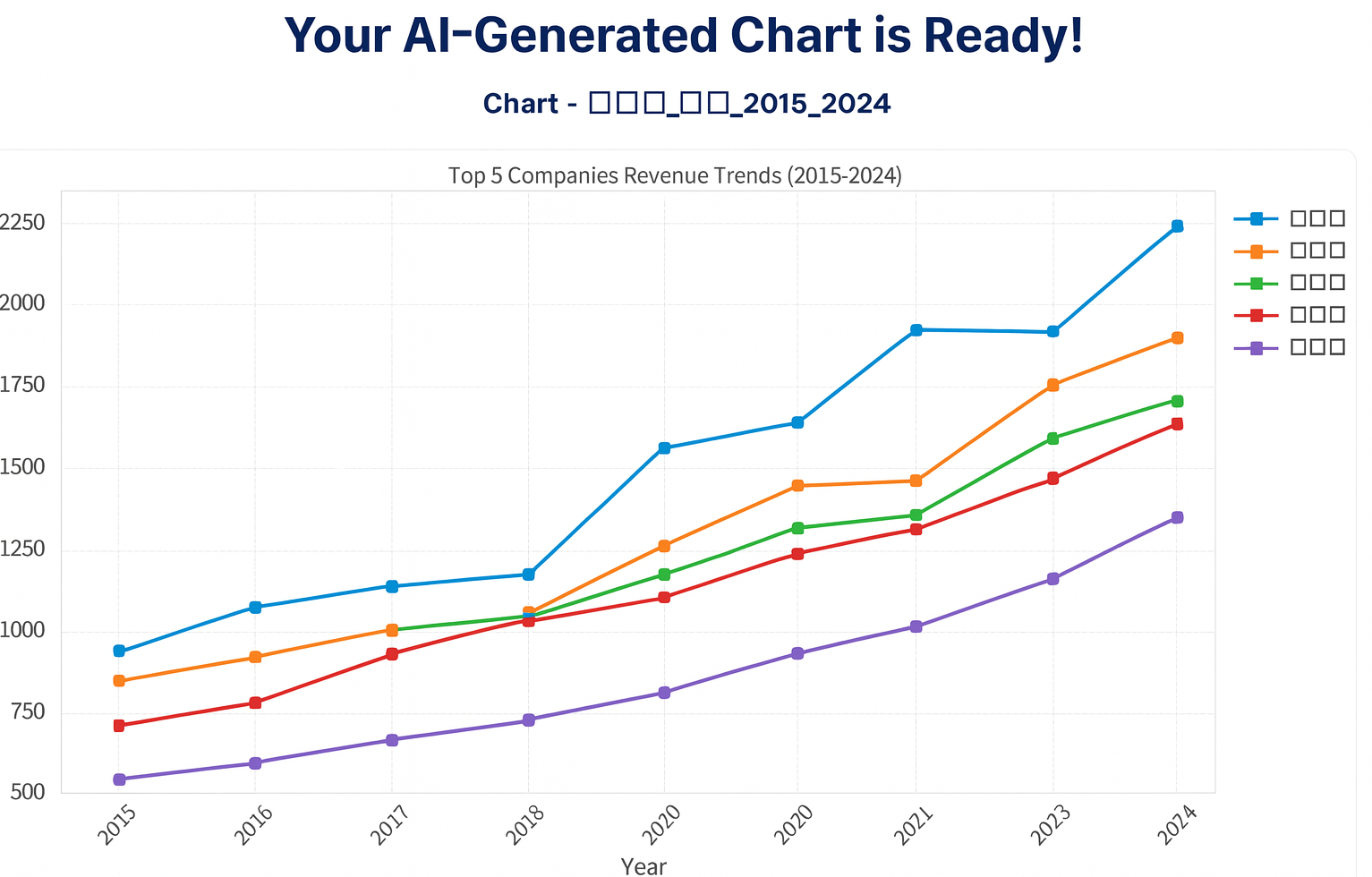 The infamous "tofu" boxes: a sign that your data tool doesn't speak your data's language.
The infamous "tofu" boxes: a sign that your data tool doesn't speak your data's language.
This isn't just an aesthetic issue. It's a fundamental failure that stops analysis in its tracks, breaks workflows, and undermines trust in your tools. At Datum Fuse, we believe this is unacceptable. That’s why we engineered our platform from the ground up to be truly global.
The "ASCII-First" Problem: Why Most Tools Fail
To understand the solution, we first need to appreciate the complexity of the problem. Handling global text is a multi-layered challenge, and a failure at any layer can corrupt your entire analysis.
Layer 1: The Encoding Minefield
When you save a text file, the characters are encoded into bytes. The old American standard, ASCII, was simple but only supported 128 characters—barely enough for English. The modern global standard is Unicode (most commonly implemented as UTF-8), which can represent over 150,000 characters from every language on Earth.
The problem arises when a tool assumes a file is UTF-8 when it might be an older encoding like cp1252 (common in Europe) or Shift-JIS (Japanese). This leads to a UnicodeDecodeError, a cryptic error that can stump even technical users. A robust tool must be able to intelligently detect and handle these different encodings.
Layer 2: The Font "Glyph" Gap
Even if a tool successfully reads the data, it needs a font to display it. Fonts are like dictionaries of character shapes, called "glyphs." A standard font like Arial or Times New Roman might contain a few hundred glyphs for Latin characters. A Korean dataset, however, requires thousands of unique Hangul syllable glyphs.
If the tool's rendering engine tries to display a Korean character using a font that doesn't contain the glyph for it, it has no choice but to render the "missing character" symbol: □. This is the source of the "tofu boxes" that plague so many data visualizations.
The Datum Fuse Solution: DatumFuse.AI's Unicode-First Architecture
We knew that to build a truly intelligent and reliable data platform, we couldn't treat global language support as an afterthought. It had to be a core architectural principle. Here’s how we solved it.
1. Intelligent Ingestion
Our file readers don't just assume UTF-8. When a user uploads a file, our system runs a series of checks, intelligently attempting to decode the file with a prioritized list of the world's most common encodings. This multi-step process dramatically reduces UnicodeDecodeError failures and ensures the data is read correctly from the start.
2. A Universal Font System
We solved the "tofu box" problem by building our charting engine on a pan-Unicode font stack. We utilize powerful font families to provide a single, harmonious font styles that covers all of Unicode.

When you generate a chart in Datum Fuse, our backend intelligently analyzes the text in your data and applies the correct font subset. Whether your data contains English, Korean, Japanese, Chinese, or Cyrillic, our system has the glyphs to render it perfectly.
The Result: From Broken Boxes to Beautiful Insights
Let's look at a real-world example. We took a public dataset of AI services, which happened to have column headers and data in Korean.
When this data is run through a standard, non-Unicode-aware plotting script, you get the predictable, useless result on the left. When it's run through Datum Fuse, you get the beautiful, perfectly legible chart on the right.
Standard Tool Result
Datum Fuse Result
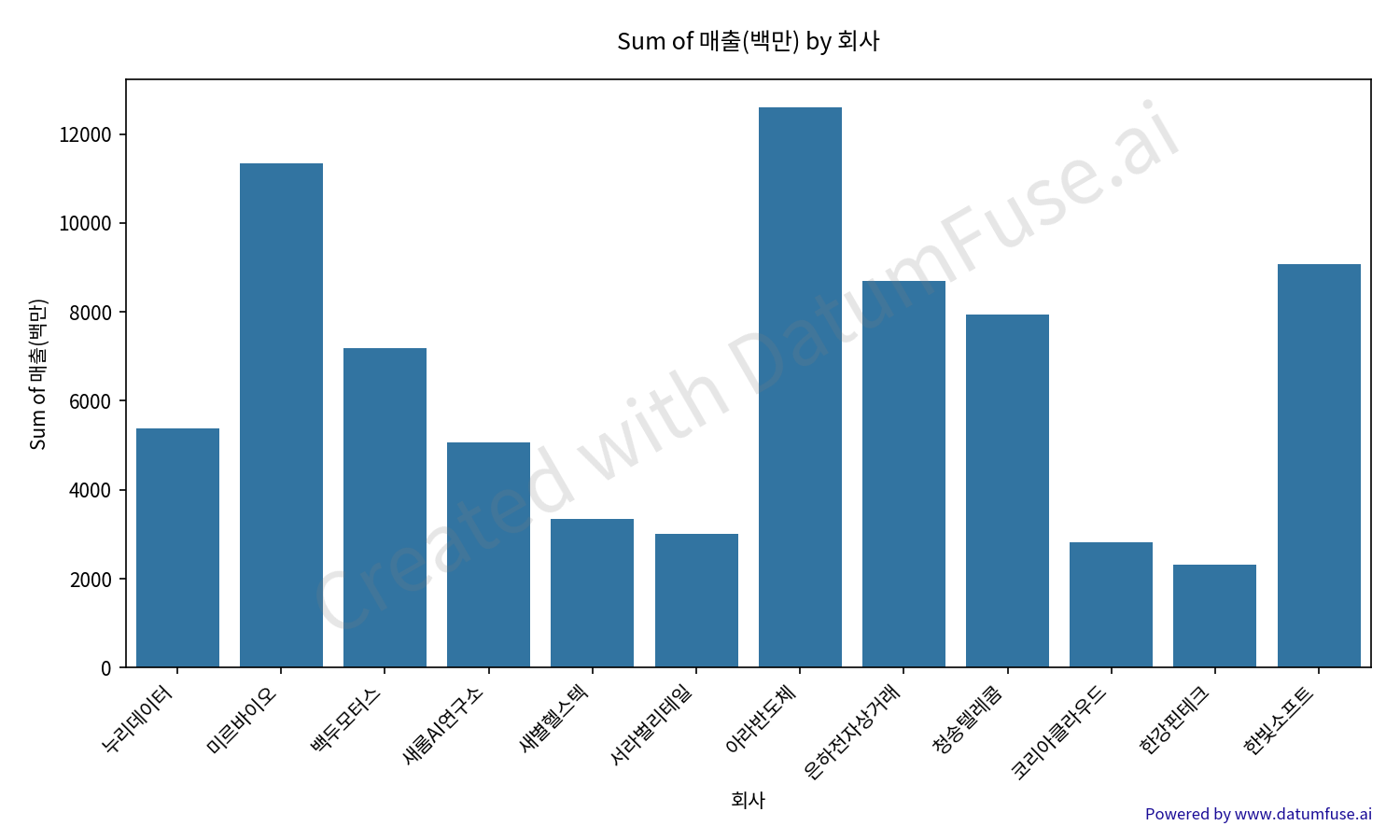
This isn't just a prettier picture. It's the difference between a failed analysis and a successful discovery. It's the difference between a tool that creates friction and a tool that creates flow.
Our Commitment: Your Data, In Your Language
The world is not monolithic, and your data reflects that. Building a platform that respects and understands the global, multilingual nature of information is a non-negotiable for us. Full, native Unicode support isn't just a line item on a feature list; it is a core expression of our mission to make data analysis truly accessible to everyone, everywhere.
Whether you're analyzing sales data from Tokyo, customer feedback from Berlin, or social media trends from São Paulo, you can be confident that Datum Fuse will handle your data with the fidelity it deserves.
Ready to try a data platform that speaks your language?